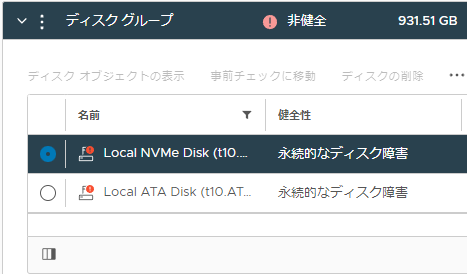
vCenter Serverにログインすると不穏なエラーが…

…というわけで、vSANのディスクエラーを対処していきます。。。(対処しながらこれ書いてるw)
作業方針
今回の環境は自宅の検証環境…ということで、リソース面でも余裕がある&一時的に冗長性がなくなっても最悪困らない(ちょっとは困る)ので、以下の流れで作業します。
- 該当のESXiホストを切り離す(ディスクエラーなので、中身が退避できるとは思ってない&できたとしても時間食うだけなので、退避はしない)
- 該当のディスクを初期化する(おそらく論理破壊でデータの不整合が発生しただけで、物理的に壊れたわけでは無いと思うので、再接続できるよう一旦リセットしてしまう)
- 初期化したディスクを、再度vSANのディスクプールに組み込む
上記作業はあくまで検証環境下での実施を想定しています。本番環境でやるときはしっかりバックアップ取るなり、VMさんにSR投げて指示された手順通りにやりましょう。本サイトに記載の方法で何か起こっても責任は取りかねます。(大事)
作業開始
まー、実はこの作業自体は以前も同様のことやったんですが、ホームユースのPCベースに組み上げた環境だとやっぱり負荷が大きすぎるんですかねぇ。故障率高めな印象です。。
っというわけで、早速作業を開始していきましょう。
状況の確認
まずは状況の確認から。。
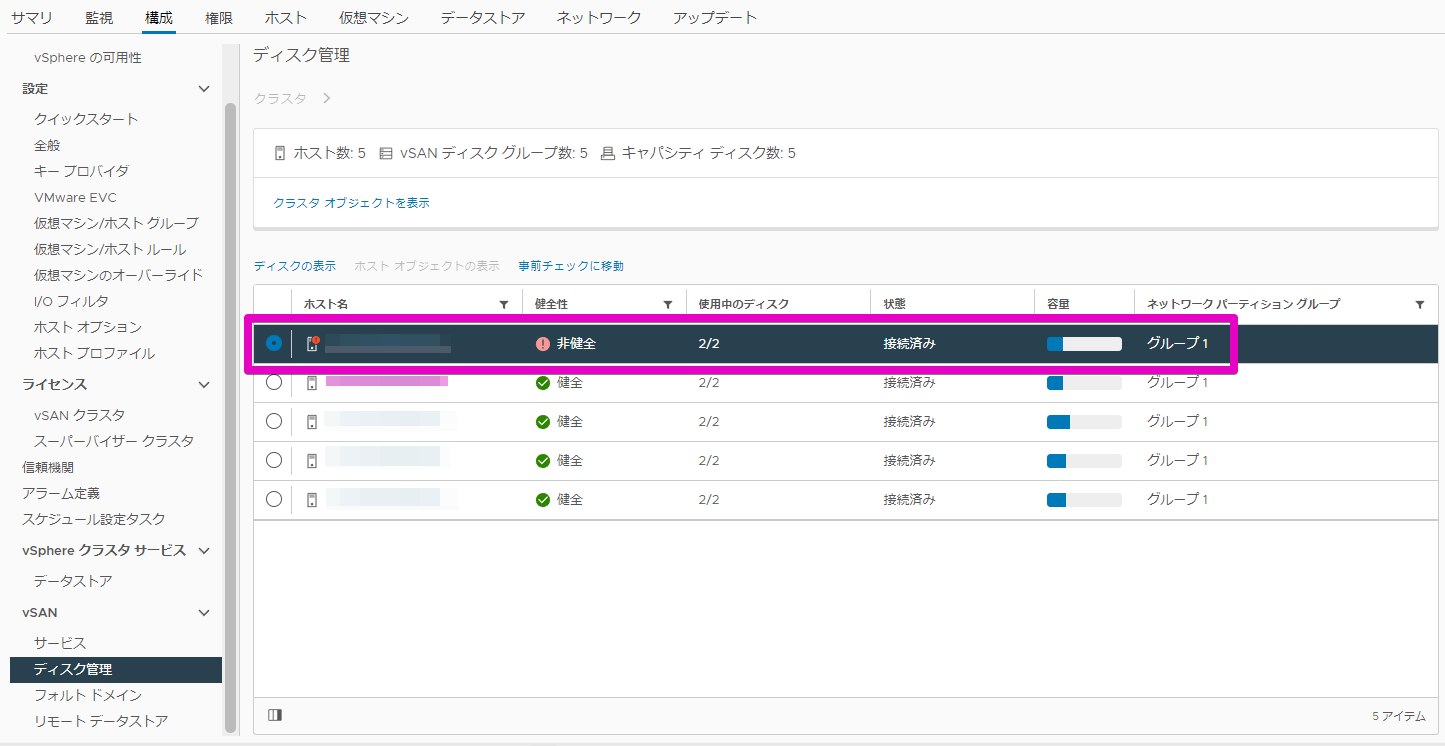
[構成] -> [vSAN] -> [ディスク管理]
を開くと、以下のような画面が開きます。思いっきり健全性がアウトな感じになってますねぇ。。。
今回は#1~5まであるうちの#2号機が故障したようです。。
[ディスクの表示] を開くと、該当のホストの中の各ディスク(キャッシュ用、キャパシティ用)の状態が見えます…が、
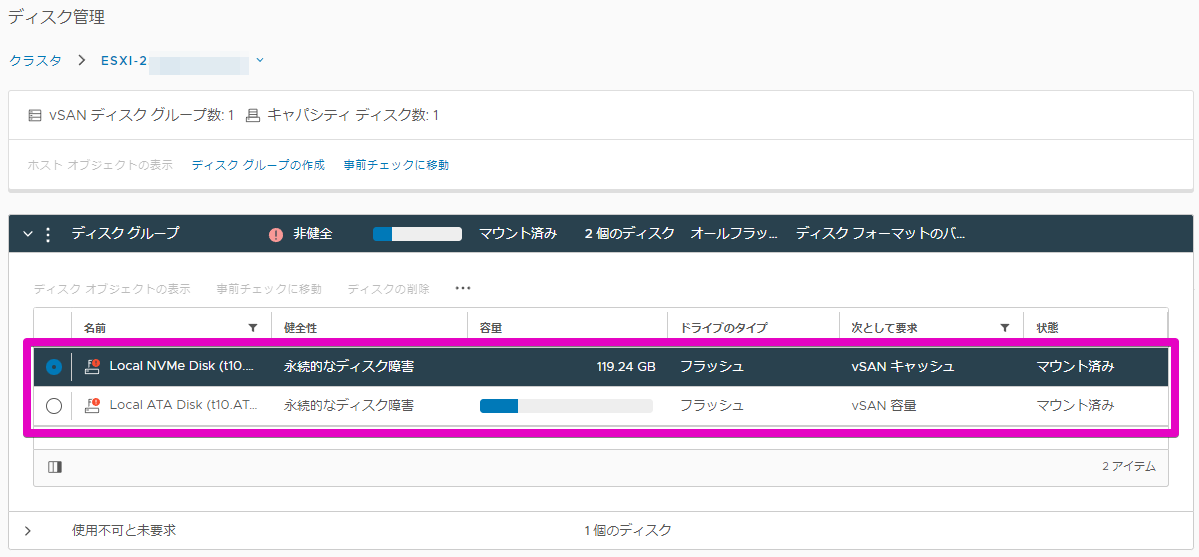
だめだこりゃ。。。
該当のESXiホストを切り離す
とりあえず、ダメになったディスクを抱えているホストを切り離します。
「永続的なディスク障害」の状態になっているので、ディスクの中身を退避する~なんてこと考えずに、スパッと切り離します。
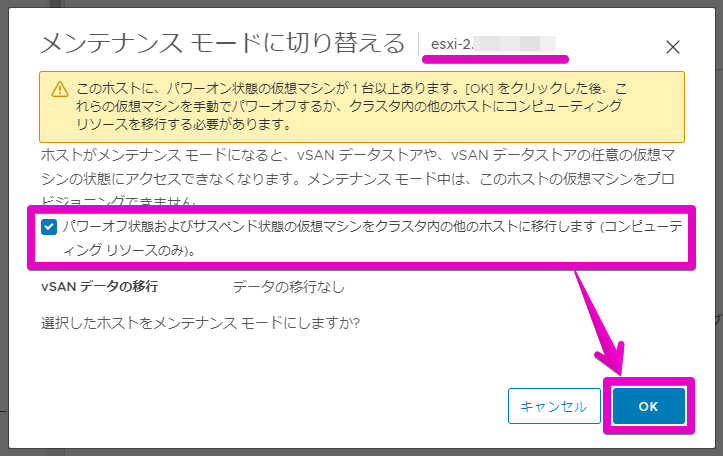
まずは、メンテナンスモードに切り替えます。
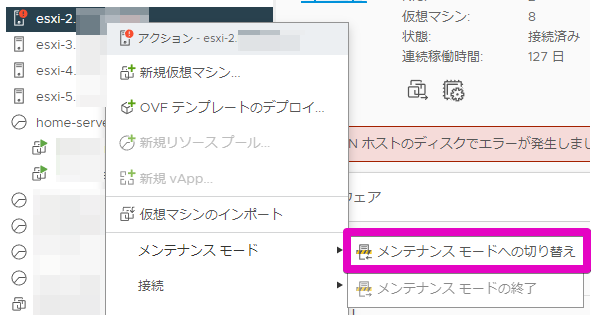
「vSANデータの移行」項目は、「データの移行なし」を選択します。
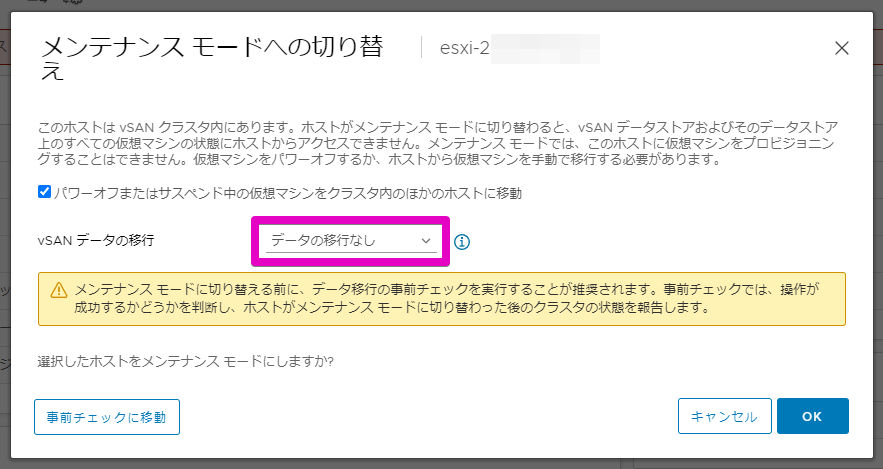
通常の作業であれば、「アクセシビリティの確保」または大事を取って「全データの移行」(時間かかるので小規模メンテだと全データまではやらないかなぁ)を選択しますが、今回はもうデータが破損しているだろう&切り離したディスクはスパッと初期化して、すぐに再接続する(≒すぐにリビルドが走らせられるディスクが用意できる短時間作業)という想定なので、これで行きます。
ディスクの初期化だけですんなり戻せれればいいんですが、ホストが実は壊れてた!?みたいなホストがすぐにクラスタに復帰できないという最悪のケースの場合にこまるので、「パワーオフまたはサスペンド中の仮想マシンをクラスタ内のほかのホストに移動」にチェックが入っていることを確認しておきましょう。
一旦この状態でOKに進む前に、[事前チェックに移動] でチェックしてみます。(念のため)
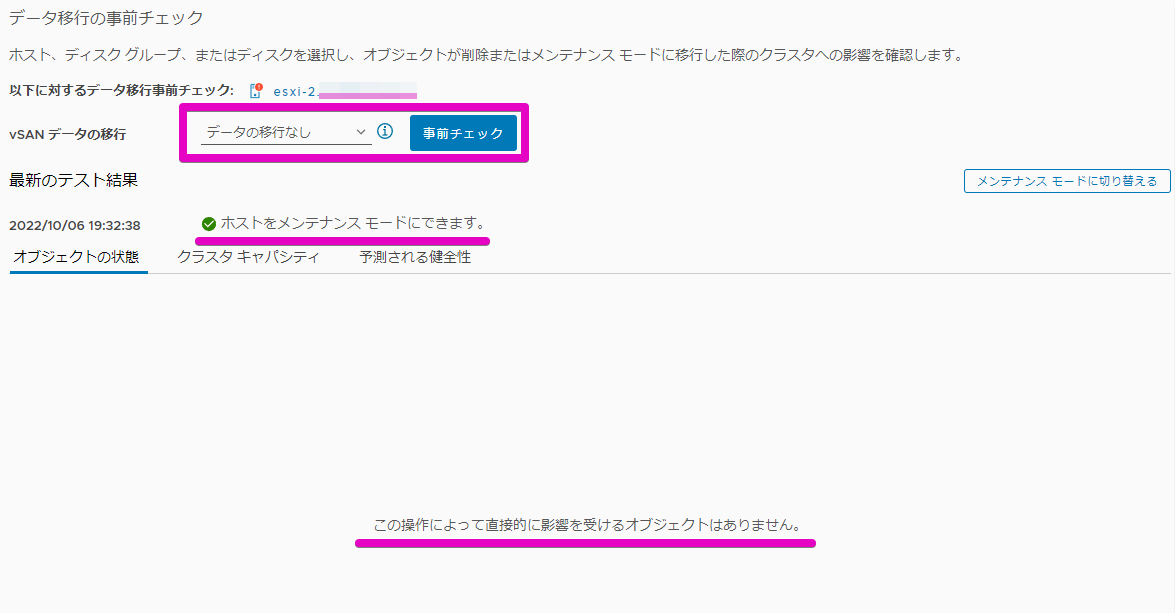
[事前チェック] ボタンをポチッと押してしばらく待つと…特に問題なさそうです。
先ほどと同じ手順、または上図右にある[メンテナンスモードに切り替える] ボタンを押してメンテナンスモードに切り替えていきます。
選択したホストに間違いがないことをよく確認して、メンテナンスモードにします。…ふぅ(緊張の瞬間)
該当のディスクを初期化する
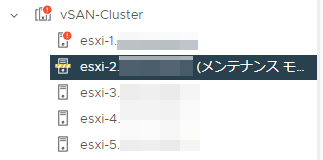
該当のホストがメンテナンスモードに入ったことを確認します。
さて、気を取り直してディスクを初期化して行きます。
該当のホストはメンテナンスモードにしただけなので、ディスクはvSANの情報が残っています。vSANの情報が残ったままのディスクはGUI上からうまく初期化できない(vSANディスクグループに参加してるディスクだから初期化できないよ!みたいなエラーがでる)ので、以下手順で強制的にその情報を取り除いてしまいます。。
内容的には上記リンクの作業となります。
まず、SSH接続してコマンド実行したいので、該当ホスト(今回は#2号機)のSSHサービスを有効化します。
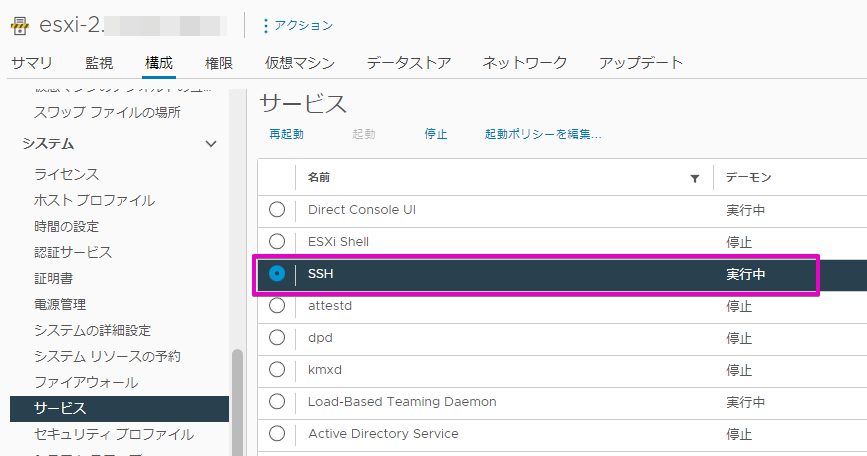
TeratermなどでSSH接続したら、
esxcli vsan storage list
コマンドを実行します。
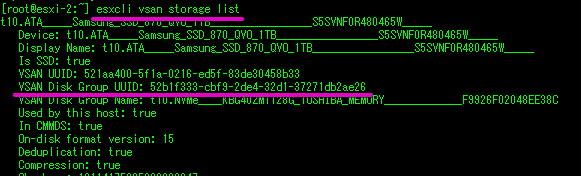
「VSAN Disk Group UUID: ~」の部分をコピーしておきます。
次に、
esxcli vsan storage remove -u <UUID>
コマンドを実行します。(先程コピーしたUUIDを使う)
![]()
ちょっと戻ってくるのに時間がかかるので内心ハラハラしますが、無事完了しました。
(2023/06/22追記)vSphere8系(ESXiが8.0U1)の環境で上記コマンドを実行したところ、30秒ほど経ってエラーが返ってくる事象が発生しました。エラー画面のスクショ撮り損ねたのですが、何らかのプロセスがうんたらかんたらみたいな記述だったので、ホストを再起動したら、無事上記コマンドが通るようになりました。
初期化したディスクを、再度vSANのディスクプールに組み込む
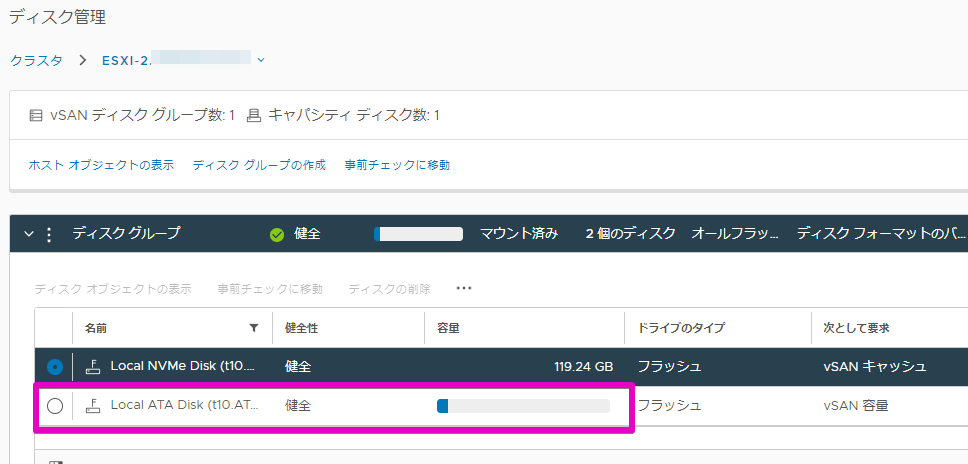
ディスクの初期化まで成功したら、vSANクラスタのディスク管理画面に戻ります。
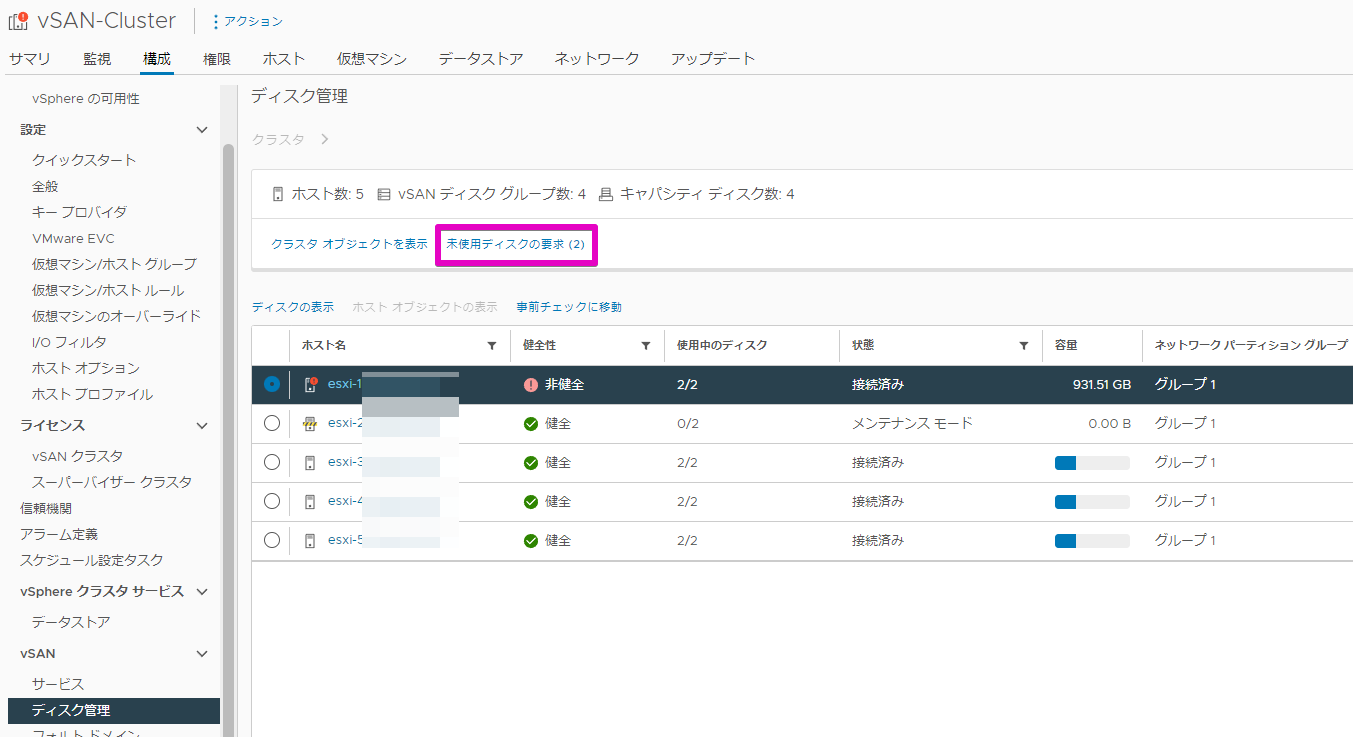
初期化されたディスクが(物理的に壊れていて接続不可とかになっていなければ…)上図のような感じで、未使用ディスクとして復活するはずです。
[未使用ディスクの要求(x)] ボタンを押下して、ディスクの追加をすすめます。
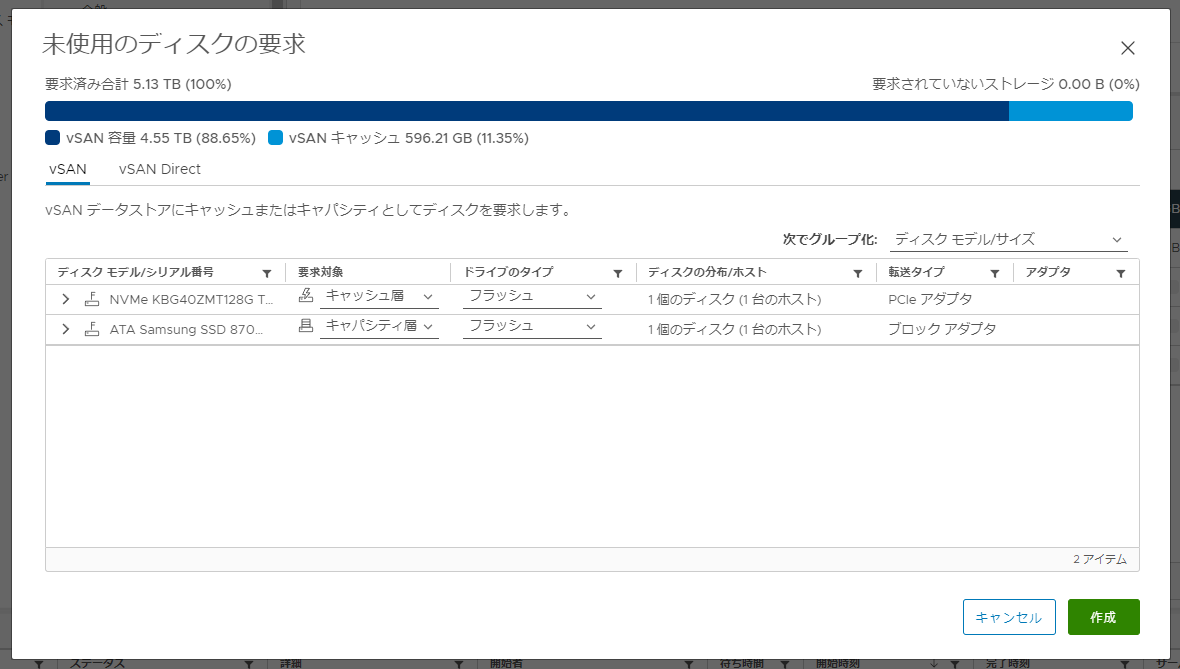
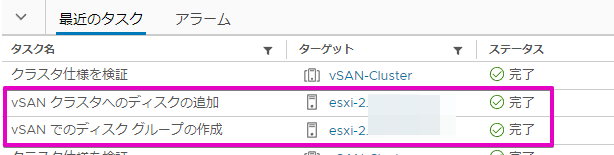
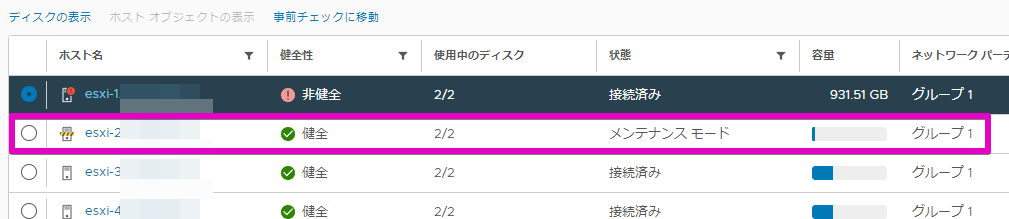
しばらくすると、このような感じで健全性が復活しました。
最後に該当ホストのメンテナンスモードを終了します。
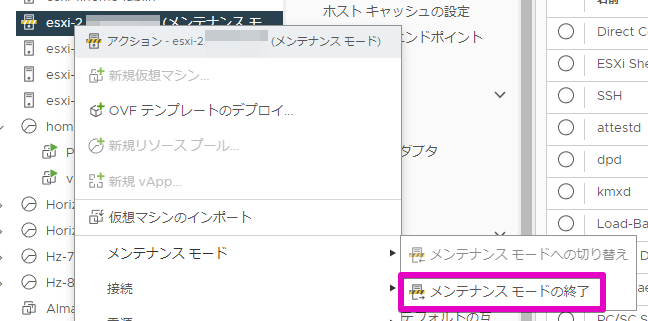
メンテナンスモード終了後、(SSHサービスも必要に応じて停止して)しばらく待つとHA構成に組み込まれるので仮想マシンの移行がどんどん走ります。
最終的にこんな感じでエラー、警告アイコンがなくなって通常アイコンに戻ればOKです。(一晩放置したせいで障害が伝播した?#1号機がエラーアイコン付いてるのはご愛嬌。。。)

しばらく経つと、こんな感じでどんどんデータも復旧されていくのがわかります。
まとめと諸注意
今回は、vSANクラスタ内のホストのディスクがすべて論理故障してしまった場合の対処について実践しました。
本番環境ではおそらく複数のキャパシティ用ディスクが構成されていていたり、ディスクの利用率がもっと逼迫していたりして、今回のようにまるっと初期化して再接続!みたいな横暴なやり方が出来なくはないが正しいとも限りません。ちゃんとSR投げて正規の手順確認しましょう。(大事なことなので何回も言う)
さーて、、#1もやるかぁ。。。(´Д`)ハァ…